Efficient and Accurate Data Labelling Tools for AI
Within the fast-growing field of AI, data labeling is a paramount process that prepares for the proper implementation of artificial intelligence models. A new data annotation tool designed to simplify work with labels has been developed by one of the leaders in AI technology, Visionbot. However, this tool provides AI development and serves as a revolution in handling and analyzing high-velocity data. The Visionbot data labeling, due to modern technology and user-friendly benefits, is the new standard for accuracy speed in AI building. When we use AI solutions to address a broad range of disciplines and try ourselves, tools like this play an essential role in creating stable outcomes that can result in significant change.
The Significance of Data Labeling in AI
Data labeling is the procedure of marking raw data (such as images, text files, or videos) and attributing one or more relevant labels to generate a concept from which a machine learning model can extract information. In this sense, data labeling forms the basis of AI training and contributes significantly to building efficient models that truly mirror human intelligence. Data annotation services are a meticulous process requiring human annotators to analyze each data point and assign the correct labels. However, this step ensures that AI models are trained on suitable datasets that match reality.
A Paradigm Shift in Data Labeling Efficiency
Labeling data, although crucial, takes much time. On the other hand, Visionbot’s data annotation services saves the day. Using powerful algorithms and intuitive interfaces, this tool greatly simplifies the process of labeling datasets in terms of time consumption and effort. Whether analyzing big data or finer details, Visionbot provides accuracy and speed – a necessary feature for AI developers and Data scientists. If they did not have this tool, performing such work would be almost impossible to do well.
Visual Content Monitoring: The Next Frontier
Visionbot also outperforms in the areas of visual content monitoring, which is parallel to data labeling. With the help of advanced technology that allows for visual image evaluation and understanding, Visionbot’s tools make it possible to monitor and control delivered content with unparalleled accuracy. This is not just a benefit for AI development but also an essential feature in many industries, such as the surveillance industry, Quality control industry, and even digital media management. For surveillance, Visionbot’s visual content monitoring can contribute to the detection and identification of targets in real time. However, in circumstances such as airports, banks, or some government buildings where security is paramount, rapid identification and response are essential. For safety precautions to be followed, effective systems must also be implemented. Visionbot’s solutions significantly contribute to production control by correctly identifying faulty or irregular products. This also does away with human inspection, thereby enhancing overall efficiency.
Revolutionizing AI with Advanced Labeling Techniques
The data labeling tools applied by Visionbot do not only include tagging valuable information. They seek to change how AI engages and uses this form of knowledge. Utilizing these resources, developers can ensure that their AI models are trained on datasets labeled with accuracy. Consequently, artificial intelligence systems produce trustworthy and practical solutions.
Empowering Industries with Efficient Data Labeling
The data labeling tools offered by Visionbot is extremely useful for various industries. For instance, in the medical world, having accurate data can help locate diseases and provide effective patient care. Autonomous vehicles depend on highly precise data annotation for safety and efficient navigation. Besides this, several other implementations across a wide range of industries could benefit from Visionbot’s advanced data labeling tools to get the full potential out of AI.
Visual Content Monitoring: Enhancing Data Integrity
In the visual content monitoring area, Visionbot claims superior technology that provides efficient solutions for ensuring the integrity and quality of visual data. It is especially crucial in fields where detailed observation can equal life and death, including security and surveillance, where monitoring depends greatly on visual data. Visionbot’s powerful capabilities guarantee accurate and reliable monitoring that maximizes protection by minimizing risk.
The Future of AI with Visionbot
The data labeling tools developed by Visionbot surpasses being a mere application. It acts as a catalyst for the development of AI technology, which confronts one of its core problems – biases. It leads to a broader inquiry into artificial intelligence by providing an effective and reliable method. With a deeper analysis of the future based on AI capabilities, tools such as Visionbot will be vital in making our world something that could only be possible with artificial intelligence. They will not only act as instruments but also evolve alongside this technology.
Dataset Labelling & Annotation
Machine learning in AI has revolutionized our approach to solving problems in computer vision and natural language processing powered by enormous amounts of data. The world of AI is constantly evolving, and recent advances in text-to-image models already transforming how artists and designers work, enabling them to experiment with their ideas and create stunning illustrations at lightning-fast speeds.
Training intelligent machines with algorithms require precise datasets that are processed using different annotation techniques and needs immense experience and expertise in various types of data annotation services viz: Collect, Curate, and Annotate data, train models and evaluate.
The role of product images and videos cannot be underestimated and the importance of investing significant resources in elaborate photoshoots. However, the expenses and time associated with live photoshoots, and the high costs and limitations of 3D rendering, pose challenges that restrict the extent to which these creative efforts can be scaled and personalized. Generative AI has emerged as a potential game-changer in this landscape. By streamlining and automating the content creation process, as well as unlocking new avenues for product visualization and hyper-personalization, generative AI has the power to revolutionize the process of improving machine learning models with high quality, diverse and large datasets.
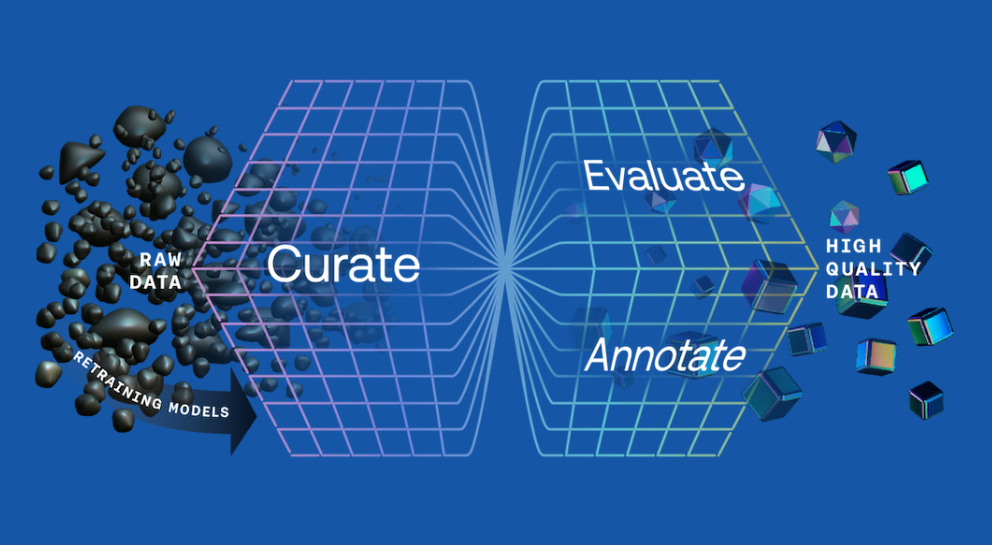
What is Data labelling & Annotation ?
Data labelling is the activity of assigning context or meaning to data so that machine learning algorithms can learn from the labels to achieve the desired result.
Machine learning has three broad categories: supervised, unsupervised, and reinforcement learning.
Supervised machine learning algorithms leverage large amounts of labelled data to “train” neural networks or models to recognize patterns in the data that are useful for a given application. For example, data labellers will label all cars in a given scene for an autonomous vehicle object recognition model. The machine learning model will then learn to identify patterns across the labelled dataset. These models then make predictions on never before seen data.
Unstructured data is data that is not structured via predefined schemas and includes things like images, videos, LiDAR, Radar, some text data, and audio data.
Image Datasets
Image data powers many applications, from face recognition to manufacturing defect detection to diagnostic imaging.
To create high-quality supervised learning models, you need a large volume of data with high-quality labels. Automated Data labelling for large datasets consisting of well-known objects, it is possible to automate or partially automate data labelling. Custom Machine Learning models trained to label specific data types will automatically apply labels to the dataset.
Building in-house tools is an option selected by some large organizations that want tighter control over their ML pipelines. You have direct control over which features to build, support your desired use cases, and address your specific challenges. However, this approach is costly, and these tools will need to be maintained and updated to keep up with the state-of-the-art.
Commercial Platforms
Commercial platforms offer high-quality tooling, dedicated support, and experienced labelling workforces to help you scale and can also provide guidance on best practices for labelling and machine learning. Supporting many customers improves the quality of the platforms for all customers, so you get access to state-of-the-art functionality that you may not see with in-house or open-source labelling platforms.
VisionBot Visual AI Studio with its experience in deep learning provides a platform for best-in-class labelling infrastructure to accelerate ML / NLP projects, with labelling tools to support any use case and orchestration to optimize the performance of your workforce. Easily annotate, monitor, and improve the quality of your data.
Types of Data Labelling?
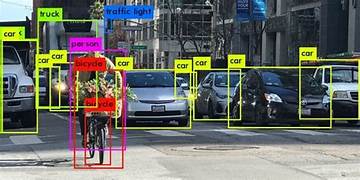
1. Bounding Box
The most commonly used and simplest data label, bounding boxes are rectangular boxes that identify the position of an object in an image or video. This box defines the object’s X and Y coordinates.
Typical Bounding Box Applications:

By “bounding” an object with this type of label, machine learning models have a more precise feature set from which to extract specific object attributes to help them conserve computing resources and more accurately detect objects of a particular type.
Object detection is the process of categorizing objects along with their location in an image. These X and Y coordinates can then be output in a machine-readable format such as JSON.
- Autonomous driving and robotics to detect objects such as cars, people, or houses
- Identifying damage or defects in manufactured objects
- Household object detection for augmented reality applications
- Anomaly detection in medical diagnostic imaging
2. Classification
Object classification means applying a label to an entire image based on predefined categories, known as classes. labelling images as containing a particular class such as “Dog,” “Dress,” or “Car” helps train an ML model to accurately predict objects of the same class when run on new data.
Typical Classification Applications:
- Activity Classification
- Product Categorization
- Image Sentiment Analysis
- Cricket Bat vs. Baseball Bat
3. Cuboids
Cuboids are 3-dimensional labels that identify the width, height, and depth of an object, as well as the object’s location.
Data labellers draw a cuboid over the object of interest such as a building, car, or household object, which defines the object’s X, Y, and Z coordinates. These coordinates are then output in a machine-readable format such as JSON.
Cuboids enable models to precisely understand an object’s position in 3D space, which is essential in applications such as autonomous driving, indoor robotics, or 3D room planners. Reducing these objects to geometric primitives also makes understanding an entire scene more manageable and efficient.

4. Polygon/Contour Annotation
Objects in an image are labelled by drawing an accurate contour around it. Used in creating datasets for training precise application models.

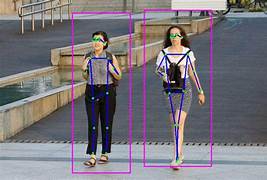
5. Key point Annotation
Objects in an image are labelled using points to determine the shape of it. Key point annotation are used to label facial/skeletal features, automotive parts etc.